On Monday I handed off K3 for a week long school trip Frauenstein. A medieval castle where they learn something about the time the castle was in full operation. Apparently that was fun as the kids not only enjoyed the activities but also bonded together and grew their relationships. That was desperately needed as the class had some challenges with separation into small groups instead of being one strong community.
Car emergencies
two car emergencies strikes this week. Somehow my wife managed to unhinge the trunk door and hit her head rather hard with it. The cut on her head looked dramatic. But fortunately she got away without an ambulance.
The next day she somehow managed to set the car on the ground with one front wheel in the air. A small field track was apparently steeper on the sides than what was visible. So I had to get to the rescue and try to get the car out. Of course we didn’t had a proper towing rope at first. Snapped two ropes I had collected from my shed earlier. We had to drive to the nearest gas station to buy a proper towing rope. That did the trick and got the car out of the trench.
This was our summer edition and last sitting before the holiday season. And it seems to be kind of a tradition meanwhile that the weather isn’t too great for outside dining. We’ve been meeting at Rembrandt Burger again and chose boldly to sit outside.
The food of course was good again. And we had fun conversing about good ol’ times and new gadgets mimicking good ol’ times 😉
Plumbing
Had to replace the faucet in the kitchen. Always fun to work in very confined space 🙄
HERE Summer Party
On Thursday we had our corporate summer party and our roof terrace and top floor. Was good to see the colleagues again in one place and also talk to some old colleagues which are still around.
We witnessed awesome clouds over Berlin
Beekeeping
My dad in law inherited the beekeeping equipment from my grandfather and is keeping up the tradition of making honey. K3 was very interested to help this week and got to uncover some honeycombs and then extract the honey. Always a spectacle for all the senses.
discovered a new Chinese restaurant in Berlin Mitte. It’s apparently authentic as you have a hard time finding labels in German or English. And the food selection is also rather exotic 🙂
They have kind of a buffet with ingredients you pick into a small basket. When you’re done, you go to the cashier and select a flavour of broth you like to have your ingredients boiled in.
The ingredients range from veggies, mushrooms over chicken feet, duck blood, chopped beef stomach to various sea foods components. Only think I was missing was insects. But maybe that doesn’t go well with broth.
It was definitely delicious
since it was very warm this week in Berlin (~ 30ºC ) I of course had to make a few cold brews with ice cubes. Always delicious and refreshing
Finally got my printer dialled in to properly print on the Zweckform labels for the automatic ASN assignment in PaperlessNGX
School concert
This school years concert of the instrumental classes at the gymnasium of K3 was again impressive. The kids really did progress with their skills over the last concert in winter. Given that most of them play the instrument only since almost a year. Especially strings don’t seem easy. Some kids are obviously more talented (and were also learning their instrument since several years at home already) than other and got a solo. One girl of the 6th grade was playing a harp – stunning.
Spicing up video conference
Took inspiration from a post on Mastodon and build a little LEGO stage to attach to the Laptop lid and spice up video conferences 😉
Weekend – Party time
On Saturday we went to a little party at friends in the next village. The weather was awesome, the food delicious and pets cuddly 😉
On Sunday we participated in the first herbal hike in our village. A local lady who’s quite knowledgeable about local herbs and their application for medical and cosmetic usage took a small group of people in a hike through the meadows and forest. She was showing us the various plants and explained how to identify them and what they might be used for. Quite interesting.
Cooking
Kiddo loves pasta. And she also loves cooking herself. So we went to make proper Spaghetti Carbonara. You don’t use cream! Just pancetta, egg yolk, grated pecorino cheese and a few spoons of the pasta water. That makes for a very creamy and rich carbonara.
Paperless Document Workflow improvements
I read an article about how to improve the document archiving process with PaperlessNGX. One basically wants some sort of clue between the paper document and the scanned digital copy. So that when you have either document, you can quickly find its counterpart. Paperless has a field for Archive Serial Number (ASN). You can sequentially number your documents if you want. Now you’d also want that serial number on the original paper document as a tie between the original and its digital copy. The trick is, to put a tiny sticker with a pre-generated ASN on the documents before scanning. Paperless can detect this ASN and use it as the serial number of the scanned document.
I was following the instructions in this article to enable the respective settings in my PaperlessNGX setup.
Paperless gets the ASN from QR codes. The stickers container QR codes and a text representation of the ASN for humans to read. The article also contains a link to a Python script which can generate sequential QR codes for various label papers.
I ordered the Avery Zweckform L4731 stickers which are 25,4mm x 10mm small. They fit on almost every document and are still readable. The trickiest part was to print them properly. The python generated labels didn’t seem to fit properly. The margins seems to be off at the top and bottom of the paper and thus the labels were overlapping the cut out stickers. I found out that one can also easily generate the stickers on the website of Avery Zweckform. They have an online editor for the labels which can generate sequential QR Codes and sequential text numbers. At the end you’ll get a PDF generated that you can print out. My print settings had to be A4 paper and explicitly set to scale 100% (not scale to fit or something else) on my Epson WF-4830. This gave me perfect printouts on the pre-cut sticker paper.
public dinner in the village
On Saturday it was finally time for our yearly public dinner in the village. We would gather at the patio in front of the church and dine together. Everyone brings their own food to be shared with other and table cloth and tableware.
This is always a lovely occasion to meet the neighbours, have good conversations and of course good food. It always amazes me that even without coordination there no duplication of food. People just get creative and bring their specialties.
and of course I got my nails done fancy by the kid 🙂
after fixing my printers hotend (the heater was broken) I created a stencil to help put lines on plain paper. That was quick and easy in AutoCAD Fusion 360.
Gotten back into using Fusion360 I also quickly designed and printed a ring to hold the support rods for our tomatoes in place.
And finally I modified someone else’s model of a curtain clip to work with my strong neodium magnets. The original model exposed the magnets and since they are super strong the clips would come off the curtain when trying to open it.
I modified the design so that the magnets are inside the model and covered by a thin layer of filament so they wouldn’t directly touch when two clips connect. The tricky part was to insert them mid print. Took a few iterations, but now it’s working and the clips are sturdy.
Beer & Burgers
we finally managed to meet again for our irregular/regular beer and burgers meeting. The weather was a bit challenging as it was still quite chilly in the evening. It did not rain at least.
Garage
Finally took the car to the garage for it was complaining about its routine maintenance cycle. Driving through the city… always a challenge as it’s super busy. Best part is always the commute back and to the garage with public transport…
Pottery
Finally picked up our stuff from paint-your-style. My cup came out nice I’d say 🙂
Visit to Szczecin
On Saturday we took a quick visit to Szczecin in the evening. Had an awesome dinner at Karczma Polska. I had one of the best duck with red cabbage I’ve ever eaten 😉
There we have June already. About 40% of the year already gone.
Went swimming with my daughter and managed to capture a pike on photo
Resurrected an old iPod touch from the drawers as kiddo needs a dump music player for the upcoming school trip. This isn’t entirely trivial anymore. Today one usually only got streaming. Now to find digital music for offline playing is a bit of an exercise. Fortunately she loves my old music as well and also listens to a lot of podcasts that are available for download.
Next challenge is headphones with wires …
Spend quite and amount of time and filament this week to calibrate the 3D printer properly. Just to find out that the heater on the extruder eventually was broken. Fortunately I still had the old Extruder laying around and could swap out the whole thing.
Got myself a little treat off Kleinanzeigen: an old GDR Marschkompass F73 from Freiberger Präzisionsmechanik manufacturing. Thats a famous GDR compass that we used to have on the scouts club. Unfortunately I didn’t preserve my own and now had to get a used one. But it’s in decent shape after all those years and the packaging looks original as well. Only the instruction manual looks a bit odd over this scanned version here.
On Friday my daughter and me went once more to the local “Paint-your-style” shop. You can paint various items of pottery here and they’ll burn and glaze it for you to pick up. Really looking forward to pickup my new cup 😉
Aaaand another one to finally catch up on my weekly reviews …
Not too much to write about actually. So might just do a photo dump. Weekends are still largely occupied by dealing with the firewood. Still splitting and stacking.
On recommendation of Blumi I gave Espresso/Tonic another try. Had in once at “The Barn” and didn’t like the sparkly coffee at all. But with ice cubes and a decent tonic it’s actually not that bad. At most as weird as my usual Orangespresso 😉
On Wednesday we had a lovely reunion with two old friends and ex-colleagues. Nice gathering on the BRLO BRWHOUSE at Gleisdreieck. Was a bit afraid it might be too crowded as just around the corner the re:publica took place. But it was OK.
passing by Checkpoint Charly on my way back home
And because of the re:publica another good friend of mine was in town and had a bit of time to meet over breakfast the next day. Again near the Gleisdreieck … so another city bike ride.
I did not attend the re:publica this year. Couldn’t be bothered to be honest. Which is also a bit of the essence of the format I guess. When it started we had these central social network that everyone was on. Now it’s all scattered. The ones remaining on the Nazi-Show run by Space Karen and the others scattered across the Fediverse and some attempting commercial social networks again. The common ground seems to be gone.
finally handing out this very late review because … life 🤷♂️
Anker USB hub Ethernet Port
I had bought the Anker 565 11-in1 USB-C hub because it’s got a good review from a German tech magazine. But at some point it stopped working with its Ethernet port. The LEDs lit up briefly but the network interface didn’t show up in the OS. I tried debugging it for a while and initially thought it is a problem with Apple Silicon Macs because the adapter was working on an older Intel Mac at home. I even contacted Anker support but there were only semi-helpful. At least they were asking for some debugging information and had recommendations on cross checking etc. The adapter normally doesn’t need any drivers to be installed as macOS does contain all needed drivers already.
Eventually I narrowed it down to be an issue with my own machine as the adapter was also working on my son’s M1 MacBook Air. So no problem with the Apple Silicons.
Eventually I found a Reddit entry where people were discussing about Broadcom ethernet chipsets and their drivers. Then it came to me that I also had a specific driver package installed for an older USB-C adapter with ethernet chipset. This one was needed for that particular chip. Apparently that driver captured the device when the Anker USB-C hub was connected and crashed, rendering the ethernet port unusable.
After I deinstalled that driver the Anke USB-C Hub was working fine again with its Ethernet port … 🤷♂️
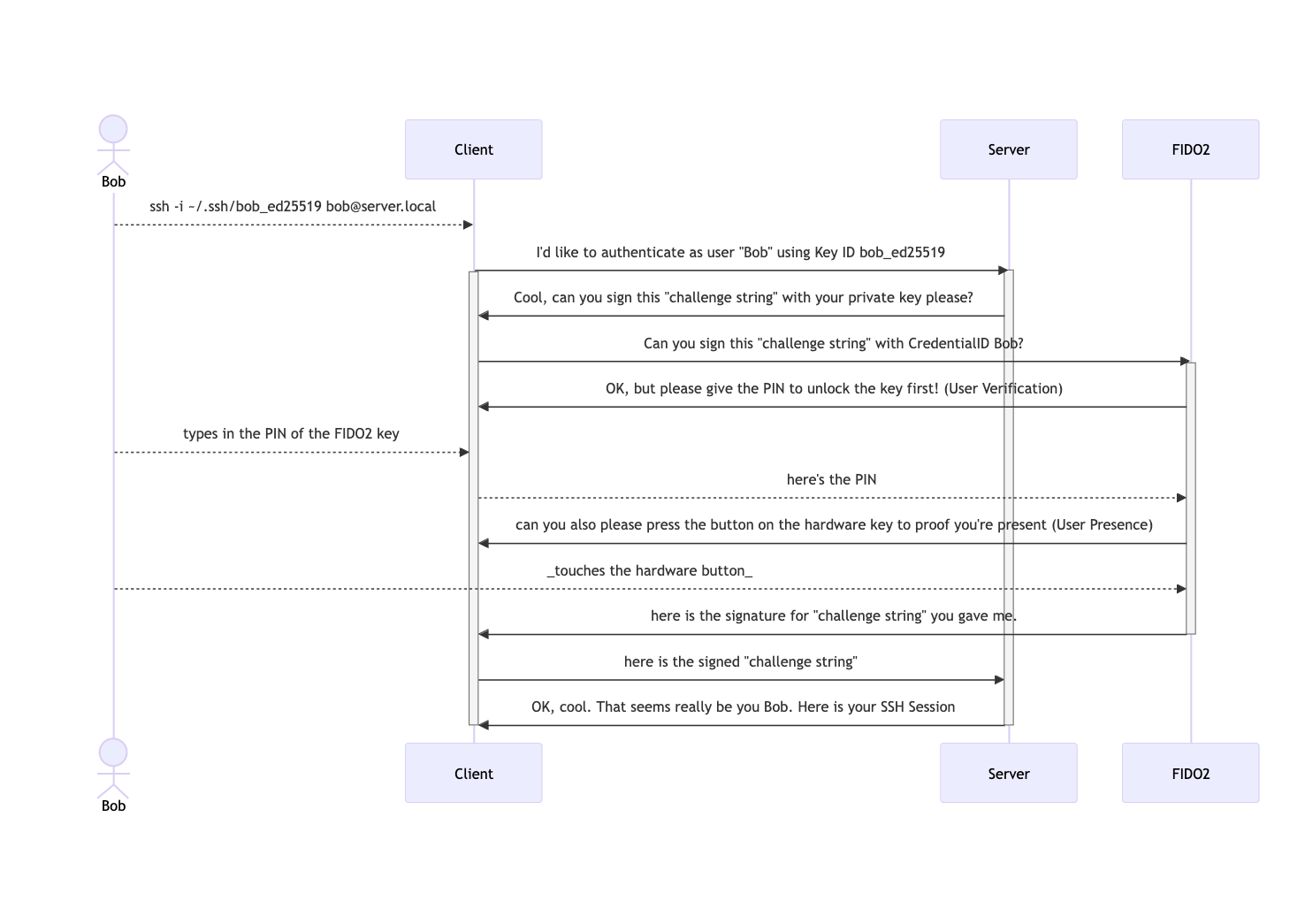
First task was to set the PIN on both. on macOS that’s the only use case where I need Google Chrome. This can configure the PIN for security keys via Settings -> Privacy & Security -> Security -> Manage Security Keys -> Create a PIN
One can also manage the individual entries on the security key via that method.
I’m using these hardware keys for Passkey authentication now. To add that physical layer of security over just storing the passkeys in my macOS/iOS Keychain or 1Password.
I use two keys and create all passkeys on both for redundancy in case I’m loosing one of them or they eventually break.
Debian BookWorm override DNS for DHCP Pihole
I’m running a bit of a convoluted network setup on my MacBook because I hate online advertisement. The best ad-blocker I’ve seen seems to be Pi-Hole. This blocks advertisement on DNS level. Means all the ad-sites just don’t resolve in the browser and rather getting a DNS error message rather quickly. That way pages load quickly without the ad and tracking parts and this solution works on all applications. Even non-browsers.
For this to work PiHole has to be your default DNS Resolver. Usually you’d get your DNS resolver via DHCP from your router. And I bet in most cases the router itself is acting as the DNS resolver as it’s the case for most FritzBox routers in Germany.
Now if you roam with your laptop between different networks you’re also switching the DNS resolver frequently. Changing your home DNS resolver to a PiHole in the home network doesn’t help when you’re in the office network or other locations.
So I opted for a Debian linux virtual machine running on my Laptop to do the blocking. I’m using UTM for virtualisation and running the Debian ARM version for performance. However I had to tell the Debian that it should get a DHCP address from hosts network stack but ignore the DNS resolver and instead use its loopback interface for DNS. This is where the PiHole software would run the DNS resolver.
Debian 12 (Bookwyrm) is using the systemd network manager. That’s why just changing the file /etc/resolv.conf doesn’t solve the problem. One has to create a file in /etc/systemd/network/ and name it like <interfacename>.network (e.q. enp0s1.network) with the following contents
As you can guess … these settings apply for all interfaces matching the Name pattern, telling systemd to do DHCP but use 127.0.0.1 as the DNS resolver and ignore the DHCP provided resolvers.
My macOS then got a special network location profile which is also using DHCP in general, but overriding the DNS resolver (I don’t know why it’s always called “DNS Server” in most settings… thats not a DNS Server but a DNS Resolver!!! ) to point to the PiHole virtual machine (which is always getting the same IP address from UTM)
On Monday the daughter of a colleague joined us in the office for a day of “Schülerpraktikum”. She was bright and curious and tried to follow us into the depth and breadth of working in a digital map making company. Hope she took something away for her
On Tuesday my personal trainer examined my exercise posture in the gym … and of course I did it all wrong. All power, no control. She tortured and lectured me for about 1 hour before we got to our weekly run.
I guess I have some homework to do now 😉
a fox casually strolling along in our backyard among the townhouses
On Wednesday I met with an old friend over beers. He was my first mentor in my first commercial job about 24 years ago. On my way back late in the evening I saw a fox casually striding along between the people “Strasse des 17. Juni”. A rather large and busy road crossing one of the many large parks in Berlin.
Thursday morning Leo and me met in Treptower Park to enjoy the good weather and work a bit outside. We both had online meetings that we took from there and I guess the colleagues on the other side of the screen where a little envious about or open office 😉
Mandarin ducks with little ducklings in the Treptower Park
On Saturday we took a trip through the countryside again to visit some plant share market, get new soap from Naturseifenmanufaktur Thoma and ended up having ice cream in Prenzlau and a visit atop the Marienkirche.
Almost time for the #weeklyreview 20/24 already. But I felt lazy this week 🤷♂️
Finally moved to a new department which was in the works for some weeks now. Take on the duty to bring back program management in our organisation to gather with a team to establish more formal business planning and operations again.
We had all this in the past and let go of it at some point. Now apparently it turned out there was value in this kind of work. Now let’s see whether we can make this more sustainable and visible this time.
The week was short due to some public holidays. Nevertheless worked on Friday which most people probably took as bridge day.
Of course there is still woodworking to do. “Convinced” (gave the choice of either one 4h session or 2 x 2hr sessions) the kid to help with the wood splitting. Almost done with the splitting now. I think another 2-3h session and we should be done with the splitting at least. Just the stacking remains. Will try to get this done over the next couple of weekends.
3D Printing
attempted one more model of a charging stand for Apple iPhone and Watch. It looks nice, but turned out to be totally unstable. My phone (iPhone 12 Pro Max) is too heavy for this stand. It always tips over, no matter which angle I mount the phone.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.WhateverRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.